연속 부분 수열 합의 개수
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(elements):
result = set()
elements = elements * 2
length = 1 # 부분수열 길이
start = 0
end = 1
while True:
if length>len(elements)//2:
break
result.add(sum(elements[start:end]))
start += 1 # 다음 인덱스로 이동
end += 1 # 다음 인덱스로 이동
if start > len(elements)//2: # 원본 elements의 마지막 요소를 지난 경우
start = 0 # 처음으로 돌아감
length += 1 # 부분 수열의 길이 +1
end = length # end는 부분 수열의 길이와 동일
return len(result)elements = elements * 2를 해준 이유는 수열이 원형으로 이어져있기 때문에
길이가 2인 부분 수열을 뽑을 때 elements[4]와 elements[0]을 뽑게 된다.
이 경우의 슬라이싱을 하려면 불편하니까 elements = [7, 9, 1, 1, 4, 7, 9, 1, 1, 4] 이렇게 연결해줘서
elements[4], elements[5]를 뽑을 수 있도록 했다.
[2468] 안전 영역
2468번: 안전 영역
재난방재청에서는 많은 비가 내리는 장마철에 대비해서 다음과 같은 일을 계획하고 있다. 먼저 어떤 지역의 높이 정보를 파악한다. 그 다음에 그 지역에 많은 비가 내렸을 때 물에 잠기지 않는
www.acmicpc.net
1) DFS 풀이
import sys
input = sys.stdin.readline
sys.setrecursionlimit(100000)
def dfs(x, y, h):
visited[x][y] = True
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0<=nx<n and 0<=ny<n:
if not visited[nx][ny] and areas[nx][ny]>h:
dfs(nx, ny, h)
n = int(input())
areas = []
for i in range(n):
areas.append(list(map(int, input().split())))
max_height = 0
for i in areas:
max_height = max(max_height, max(i))
cnt = 0
cnt2 = 0
for h in range(max_height):
visited = [[False]*n for _ in range(n)]
cnt2 = 0
for i in range(n):
for j in range(n):
if not visited[i][j] and areas[i][j]>h:
dfs(i, j, h)
cnt2+=1
cnt = max(cnt, cnt2)
print(cnt)sys.setrecursionlimit() 설정을 안 해줘서 런타임 에러가 발생했다.
재귀함수 사용할 때는 항상 setrecursionlimit 설정해주자!!!!!!!!!!!! 명심하기!!!!!!!!!!
2) BFS 풀이
import sys
input = sys.stdin.readline
from collections import deque
sys.setrecursionlimit(100000)
def bfs(x, y, h):
q = deque()
q.append((x,y))
visited[x][y] = True
while q:
x, y = q.popleft()
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0<=nx<n and 0<=ny<n:
if not visited[nx][ny] and areas[nx][ny]>h:
q.append((nx,ny))
visited[nx][ny] = True
n = int(input())
areas = []
for i in range(n):
areas.append(list(map(int, input().split())))
max_height = 0
for i in areas:
max_height = max(max_height, max(i))
cnt = 0
cnt2 = 0
for h in range(max_height):
visited = [[False]*n for _ in range(n)]
cnt2 = 0
for i in range(n):
for j in range(n):
if not visited[i][j] and areas[i][j]>h:
bfs(i, j, h)
cnt2+=1
cnt = max(cnt, cnt2)
print(cnt)
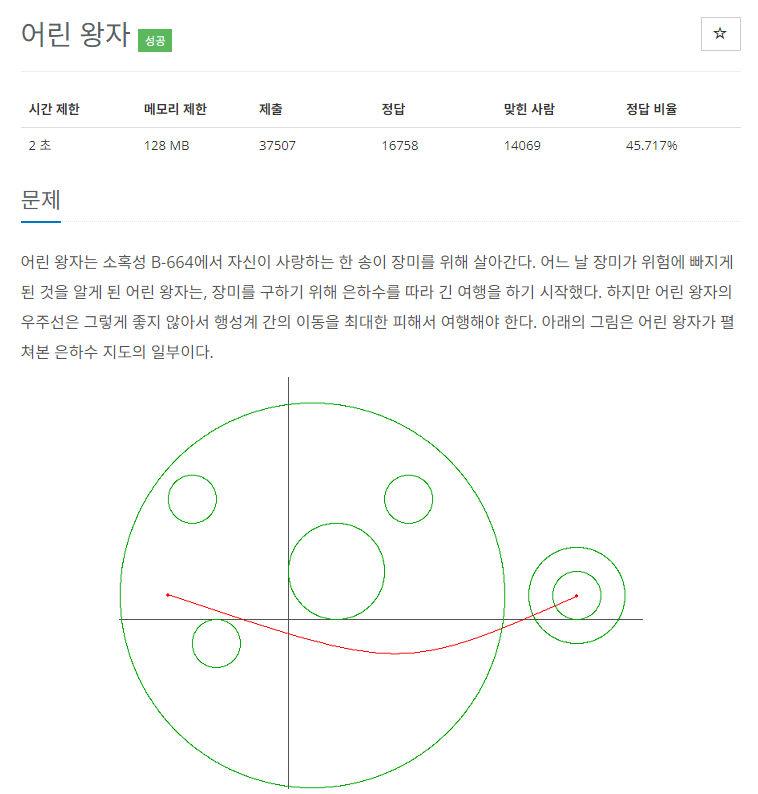
[1004] 어린 왕자

import sys
input = sys.stdin.readline
t = int(input())
for _ in range(t):
x1, y1, x2, y2 = map(int, input().split())
n = int(input())
count = 0
for i in range(n):
c1, c2, r = map(int, input().split())
# 어린왕자의 위치에서 행성의 중심까지의 거리 구하기
dist1 = ((x1-c1)**2 + (y1-c2)**2) # 출발지점
dist2 = ((x2-c1)**2 + (y2-c2)**2) # 도착지점
# 거리가 r보다 작다면 행성 내부에 있으므로 진입/이탈 필요
#츌발지점, 도착지점 모두 행성 내부에 있는 경우는 count X
if (dist1<r**2 and dist2<r**2):
pass
elif dist1<r**2:
count += 1
elif dist2<r**2:
count += 1
print(count)
항상 점의 좌표와 원의 반지름 관련이 나오면 원의 성질을 이용해서 풀 수 있는지 확인하자!
처음 풀었을 때는 예외 케이스를 고려하지 않고 그냥 작성해서 실패했다.
어린왕자의 출발 지점(or 도착 지점)에서 행성의 중심까지의 거리가 행성의 반지름보다 작으면
그 행성 내부에 어린왕자가 있다는 것을 의미한다. 즉, 진입, 이탈이 필요하다는 뜻이다.
이 경우만 고려하고 코드를 작성했고 테스트케이스 모두 맞게 출력되서 제출했더니 틀렸다.
잘 생각해 보니 출발 지점, 도착 지점 모두 한 행성 내부에 있는 경우 count가 2번 되고 있었다.
그래서 두 지점이 원의 반지름보다 작으면 아무 연산을 하지 않고 그대로 pass 해주는 코드를 작성했다.
[7568] 덩치


import sys
input = sys.stdin.readline
n = int(input())
info = []
result = []
for i in range(n):
x, y = map(int, input().split())
info.append((x,y))
for i in range(n):
cnt = 0
for j in range(n):
if i==j:
continue
if info[i][0]<info[j][0] and info[i][1]<info[j][1]: #몸무게, 키 둘 다 큰 경우
cnt+=1
if cnt==0:
result.append(1)
else:
result.append(cnt+1)
for i in result:
print(i, end=' ')
[10866] 덱

import sys
input = sys.stdin.readline
from collections import deque
n = int(input())
deque = deque()
for _ in range(n):
simulation = list(map(str, input().split()))
if len(simulation)>1:
x = simulation[1]
act = simulation[0]
if act == 'push_front':
deque.appendleft(x)
elif act == 'push_back':
deque.append(x)
elif act == 'pop_front':
if len(deque)==0: print(-1)
else: print(deque.popleft())
elif act == 'pop_back':
if len(deque)==0: print(-1)
else: print(deque.pop())
elif act == 'size':
print(len(deque))
elif act == 'empty':
if len(deque)==0: print(1)
else: print(0)
elif act =='front':
if len(deque)==0: print(-1)
else: print(deque[0])
elif act=='back':
if len(deque)==0: print(-1)
else: print(deque[-1])
전형적인 시뮬레이션 구현 문제이다.
deque를 잘 알고 있으면 쉽게 풀 수 있다.
괄호 회전하기

def result(s):
g = ['()', '{}', '[]']
while True:
found = False
for i in range(len(s)-1):
if s[i:i+2] in g:
s = s.replace(s[i:i+2], '') # 인접한 두 문자열이 올바른 괄호인 경우 공백 처리
found = True
break
if not found:
break
return len(s)
def solution(s):
answer = 0
for i in range(len(s)):
rotation = s[i:] + s[:i]
if result(rotation)==0:
answer += 1
return answer
n^2 배열 자르기

1) 오답 (시간초과)
def solution(n, left, right):
answer = []
arr = [[0]*n for _ in range(n)]
num = [i for i in range(1, n+1)]
for i in range(1, n+1):
answer.extend([i]*i)
answer.extend(num[i:])
return answer[left:right+1]
오답이지만 그래도 답을 찾아가는 과정이니 해설을 적어둬야겠다. 나중에 참고할 수 있으니!
n의 범위가 1보다 이상 10^7이하이기 때문에 2중 for문을 돌리면 시간 복잡도가 커진다.
그래서 1차원 배열로 만들 때의 패턴을 찾아서 확인해 보면
i=1
1을 1번 사용하고 1 이후의 숫자는 그대로 온다.
1 | 2 3 4
i=2
2를 2번 사용하고 2 이후의 숫자는 그대로 온다.
2 2 | 3 4
i를 i번 사용하고 i 이후의 숫자는 그대로 온다
i i i ~ | i+1 ~
2) 정답
def solution(n, left, right):
answer = []
for i in range(left, right+1):
result = max(i//n, i%n)
answer.append(result+1)
return answer
| i | i//n | i%n | result |
| 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 2 |
| 2 | 0 | 2 | 3 |
| 3 | 1 | 0 | 2 |
| 4 | 1 | 1 | 2 |
| 5 | 1 | 2 | 3 |
| 6 | 2 | 0 | 3 |
| 7 | 2 | 1 | 3 |
| 8 | 2 | 2 | 3 |
left 값에 n을 나눈 몫, 나머지르 적고 answer에 저장되는 result값도 따로 적어봤다.
몫과 나머지 중 큰 값을 선택해서 +1을 해주면 그 값이 answer에 저장되는 result 값이 되는 것을 찾아냈다.
몫과 나머지의 값이 같으면 아무거나 선택해서 +1을 해주면 된다.
할인 행사

def solution(want, number, discount):
answer = 0
dic = {}
for i in range(len(want)):
dic[want[i]] = number[i]
for i in range(len(discount)):
d = discount[i:10+i]
check = True
for i in want:
if dic[i] != d.count(i):
check = False
break
if check:
answer += 1
return answer
처음에는 편하게 쓰고 싶어서 딕셔너리를 이용했는데, 딕셔너리 없이도 풀 수 있어서
아래 코드처럼 작성하고 최종 제출했다.
def solution(want, number, discount):
answer = 0
for i in range(len(discount)):
d = discount[i:10+i]
check = True
for i in range(len(want)):
if number[i] != d.count(want[i]):
check = False
break
if check:
answer += 1
return answerH_index

def solution(citations):
answer = 0
for i in range(max(citations)+1):
cnt1 = 0 # i회 이하 인용된 논문의 수
cnt2 = 0 # i회 이상 인용된 논문의 수
for j in citations:
if i<=j:
cnt1 += 1
if i>=j:
cnt2 += 1
if cnt1>=i and cnt2<=i:
answer = max(answer, i)
return answer
h회 이하 인용된 논문의 수가 h개 이하여야 하고, h회 이상 인용도니 논문의 수가 h개 이상이어야 한다.
이 부분을 명확하게 이해해야 하고, h_index의 최댓값을 구해야 하므로 조건에 만족한 answer이 이전 answer 값보다
큰 경우에는 업데이트 해줘야 한다.
[0, 1, 4, 5]가 주어졌다고 치자,
0회 이상 인용된 논문의 수는 4개로 0개 이상 조건에 충족된다.
0회 이하 인용된 논문의 수는 1개로 0개 이하 조건에 충족되지 않는다.
1회 이상 인용된 논문의 수는 3개로 1회 이상 조건에 충족된다.
1회 이하 인용된 논문의 수는 2개로 1회 이하 조건에 충족되지 않는다.
2회 이상 인용된 논문의 수는 2개로 2회 이상 조건에 충족된다.
2회 이하 인용된 논문의 수는 2개로 2회 이하 조건에 충족된다.
조건에 충족되기 때문에 h_index는 2가 된다.
3회 이상 인용된 논문의 수는 2개로 3회 이상 조건에 충족되지 않는다.
3회 이하 인용된 논문의 수는 2개로 3회 이하 조건에 충족된다.
4회 이상 인용된 논문의 수는 2개로 4회 이상 조건에 충족되지 않는다.
4회 이하 인용된 논문의 수는 3개로 4회 이하 조건에 충족된다.
def solution(citations):
citations = sorted(citations)
l = len(citations)
for i in range(l):
if citations[i] >= l-i:
return l-i
return 0
검색을 해보니 이런 식으로 많이 풀더라.
citations를 오름차순으로 (인용 횟수가 작은 논문부터 큰 논문 순으로) 정렬한다.
논문의 수만큼 반복문을 실행한다.
각 논문의 인용 횟수가 전체 논문 횟수에서 현재까지 남아있는 논문 수보다 크거나 같은 경우,
해당 값이 H-Index가 된다.
sorted 함수 호출로 인해 시간 복잡도는 O(nlogn)이 발생한다.
내가 작성했던 코드는 2중 for문을 돌리기 때문에 위 코드처럼 작성하는 것이 훨씬 효율적이다.
[0, 1, 4, 5]가 주어졌다고 치자,
l = 4
0 >= 4-0 충족 X
1 >= 4-1 충족 X
2 >= 4-2 충족 O
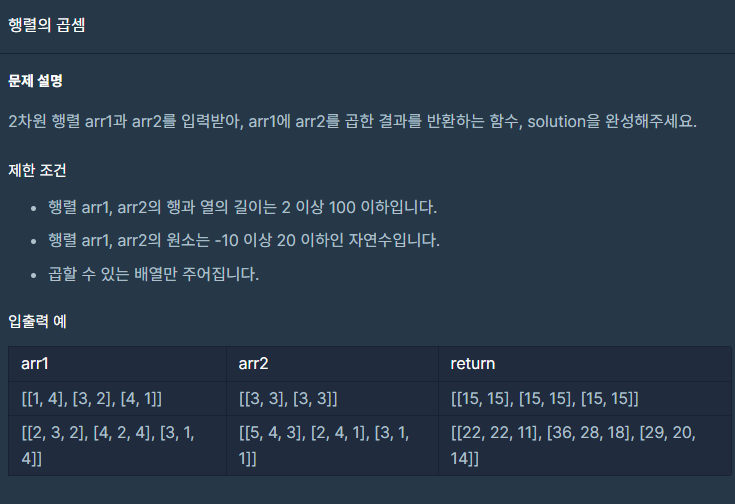
행렬의 곱셈
def solution(arr1, arr2):
# 전치 (행<->열 바꾸기)
arr2 = list(zip(*arr2))
# arr1의 행 수 * 기존 arr2의 열 수(= 전치한 arr2의 행 수)
answer = [[0] * len(arr2) for _ in range(len(arr1))]
for i in range(len(arr1)):
for j in range(len(arr2)):
result = [x*y for x,y in zip(arr1[i],arr2[j])]
answer[i][j] = sum(result)
return answer
m*k인 행렬과 k*n의 행렬을 곱하면 m*n의 행렬이 나온다.
문제에서는 곱할 수 있는 행렬만 입력된다고 했으니 k조건은 파악하지 않아도 된다.
계산을 쉽게 하기 위해 나는 arr2의 행과 열을 바꿨다. (전치)
이렇게 하면 arr1과 arr2의 행끼리 곱해주면 된다.
answer 배열의 크기를 결정할 때 전치하지 않았다면 len(arr2[0])이 정답이지만,
나는 전치했기 때문에 arr2의 행의 크기인 len(arr2)로 작성했다.
result = [x*y for x,y in zip(arr1[i],arr2[j])]
이 부분은 arr1의 행과 arr2의 행에 있는 요소들을 각각 곱해준 값을 리턴한다.
zip 사용 예시)
list1 = [1,2,3]
list2 = [4,5,6]
for i,j in zip(list1, list2):
print(i,j, i*j)출력
1 4 4
2 5 10
3 6 18
의상

def solution(clothes):
cloth = {}
ans = 1
for i in clothes:
if i[1] in cloth: # 해당 옷 종류가 있을 경우
cloth[i[1]] += 1
else: # 해당 옷 종류가 없을 경우
cloth[i[1]] = 1
for i in cloth.values():
ans *= (i + 1) # 안 입는 경우 포함하기 위해 +1 처리
return ans - 1 # 아예 안 입는 경우 빼주기'Algorithm' 카테고리의 다른 글
| 백준 알고리즘 문제 풀이 (0) | 2023.09.15 |
|---|---|
| [이코테] 그래프 이론 (0) | 2023.09.13 |
| 백준, 프로그래머스 다양한 문제 풀이 (1) | 2023.09.08 |
| [백준] 문제 풀이 (0) | 2023.09.06 |
| [프로그래머스] level2 (0) | 2023.09.05 |



